大学生创新训练计划项目管理系统
大学生创新训练计划项目管理系统
2023
基于机器学习的无人车群协同技术的开发与设计
盲选
创新训练项目
工学
计算机类
B、学生来源于教师科研项目选题
创新类
2023-04
2024-04
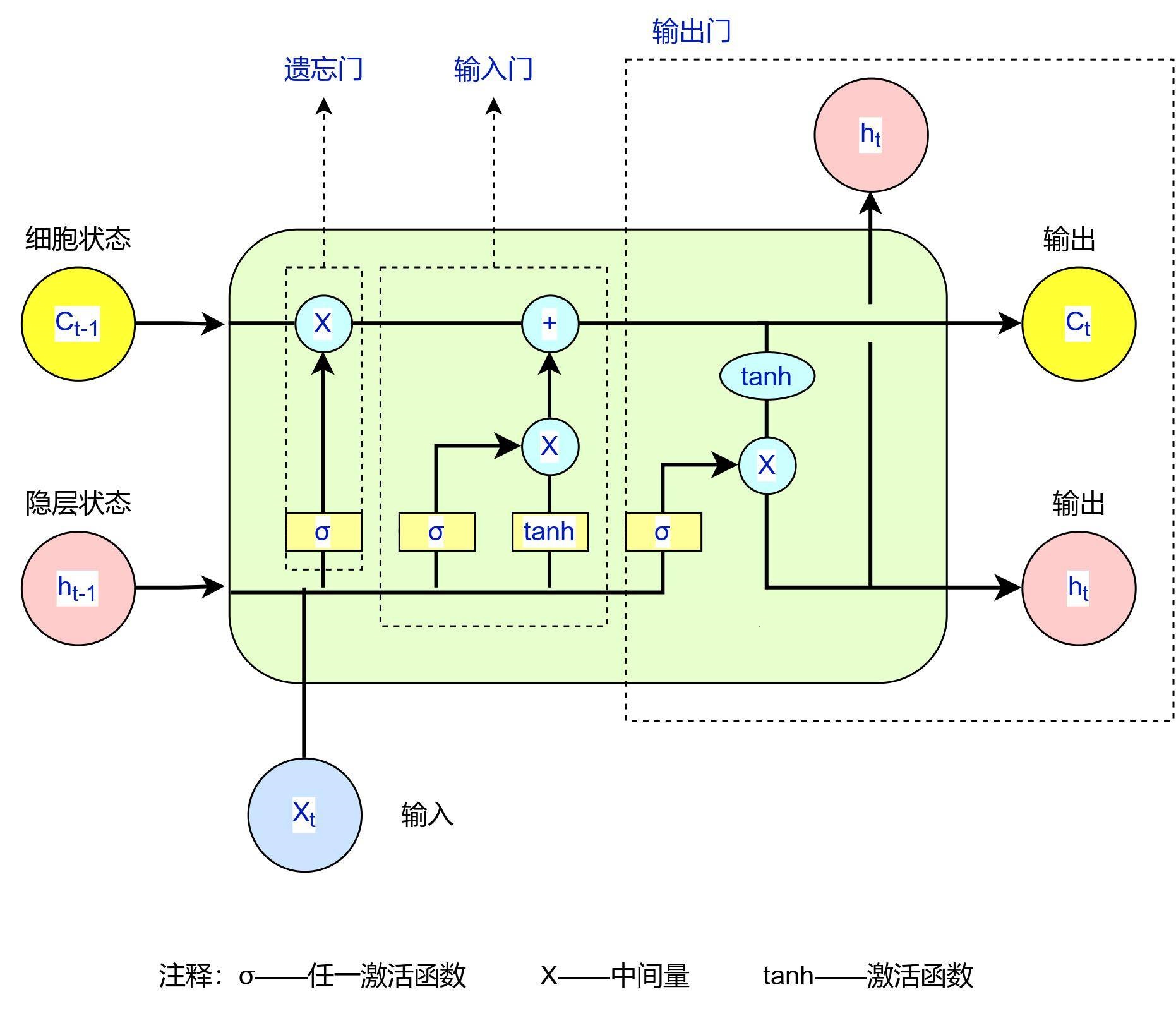
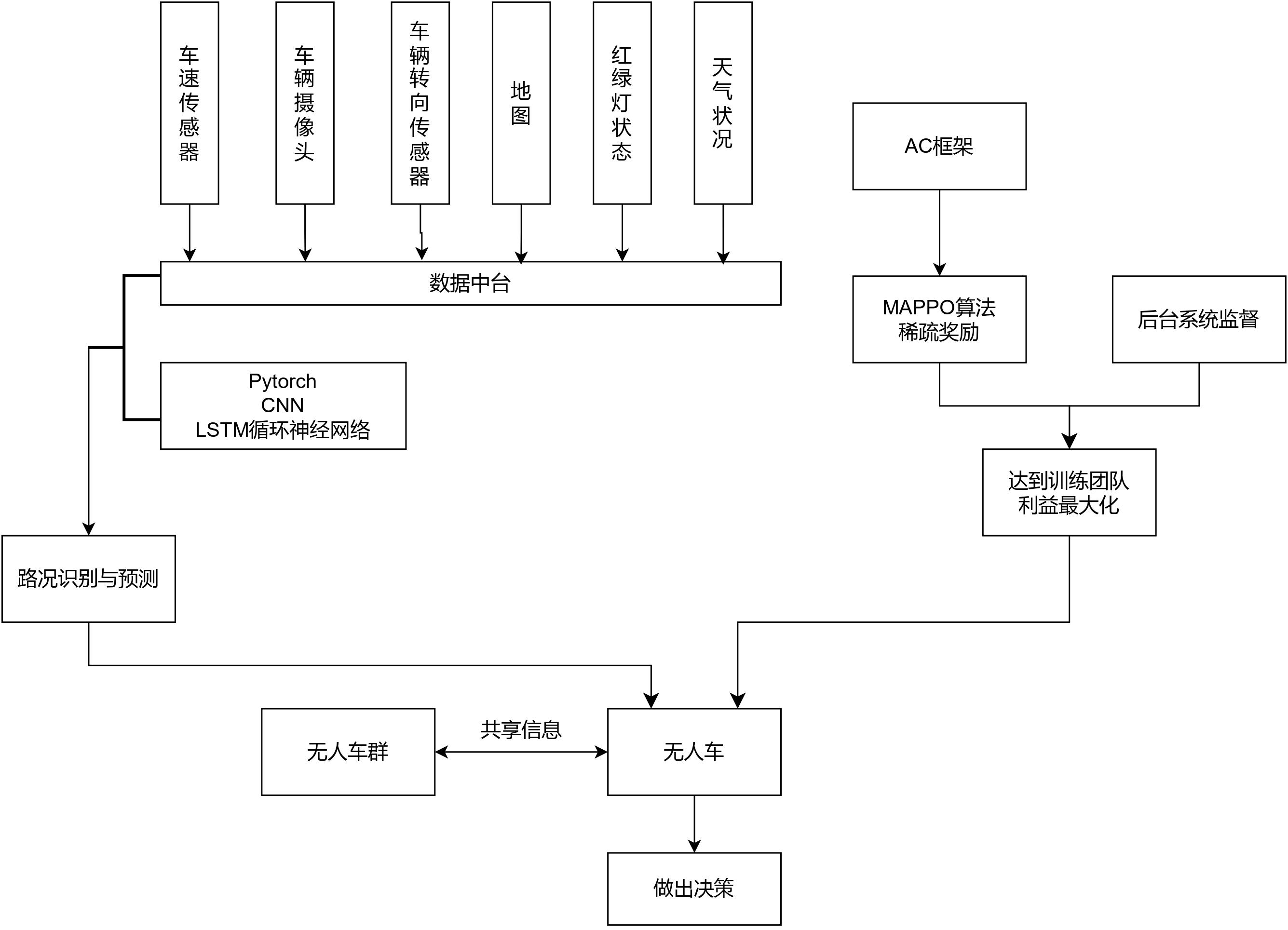
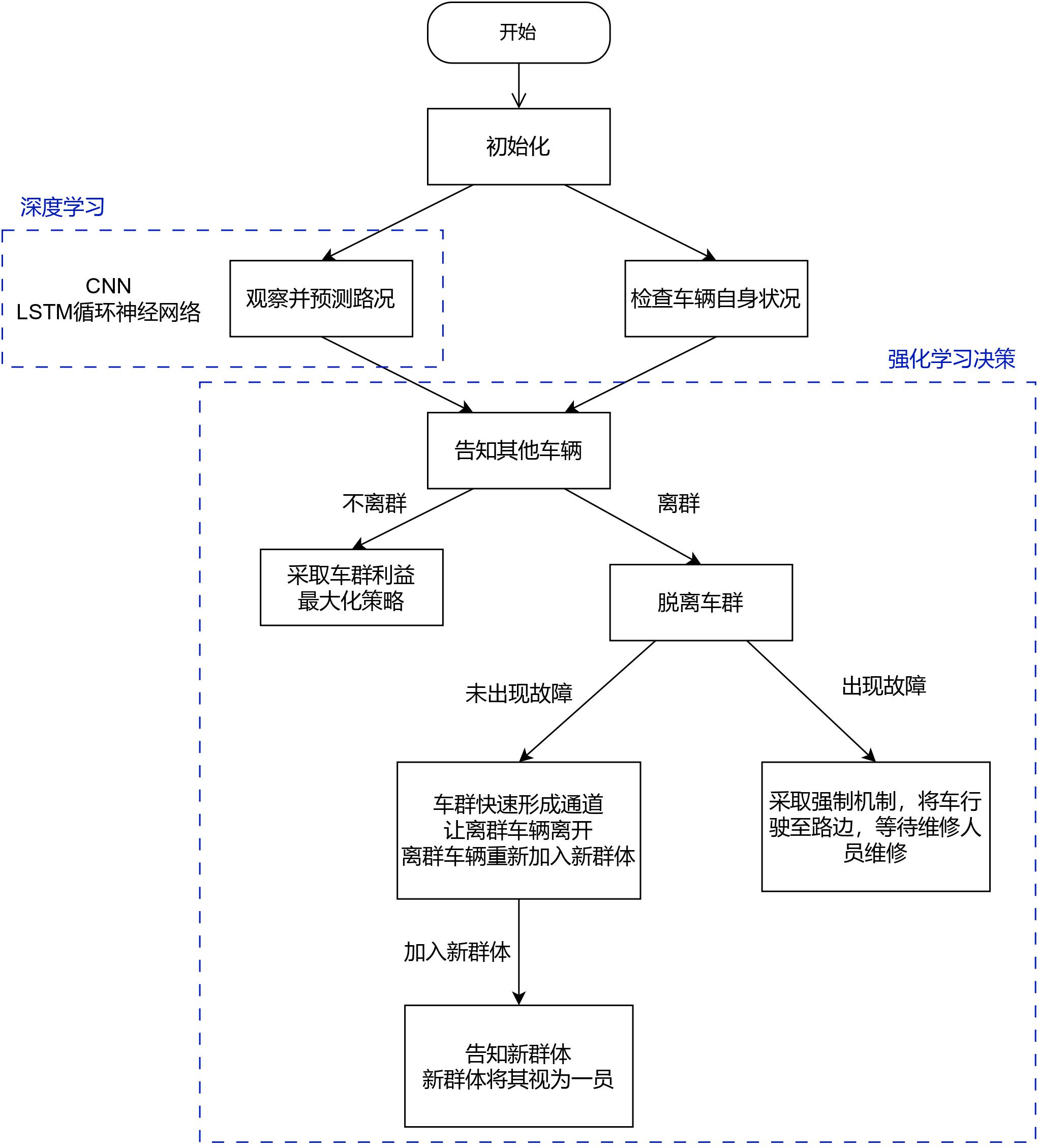
本项目采用了深度强化学习来训练无人车群,使其安全与稳定。现实存在无人车群与有人驾驶车混合的情况,因此需要设置系统,使各无人车能自动形成车群,与有人车隔离。在行驶过程中,无人车通过卷积神经网络(CNN)与LSTM 循环神经网络相结合做出决策。在训练过程中,挑选合适的数据集进行训练,并且设定确切的初始值和合适的奖惩机制。拟用稀疏奖励和 MAPPO 算法,让无人车更加倾向于做群体利益最大化。
参与蓄电池废液无害化排放的相关实验。
指导教师苗国英副教授自2009年以来,一直从事多智能体系统的协调控制的研究。比较熟悉多智能体系统的协调控制研究现状、前沿动态以及需要解决的问题,具体的科研情况如下:
1.主持并完成多项省级和国家级项目,其中包括国家自然科学基金青年项目(No.61503189)一项、主持江苏省自然科学基金青年项目(No. BK20150926)一项、主持国家自然科学基金面上项目(No.62073169)一项、 中国博士后基金(No.2016M591745)一项、 江苏省博士后基金(No.1501039B)一项等。
2. 在多智能体领域,取得了一系列创新性研究成果,指导教师苗国英副教授以第一作者在国内外主流期刊发表十余篇论文。同时,积极指导多名本科生和研究生撰写发明专利、实用新型和软著等。
3.基于在多智能体领域的突出的科研成果,指导教师苗国英副教授荣获江苏省自动化学会科学技术奖、以及中国自动化学会二等奖。
导师提供相关知识、技术的指导。
校级


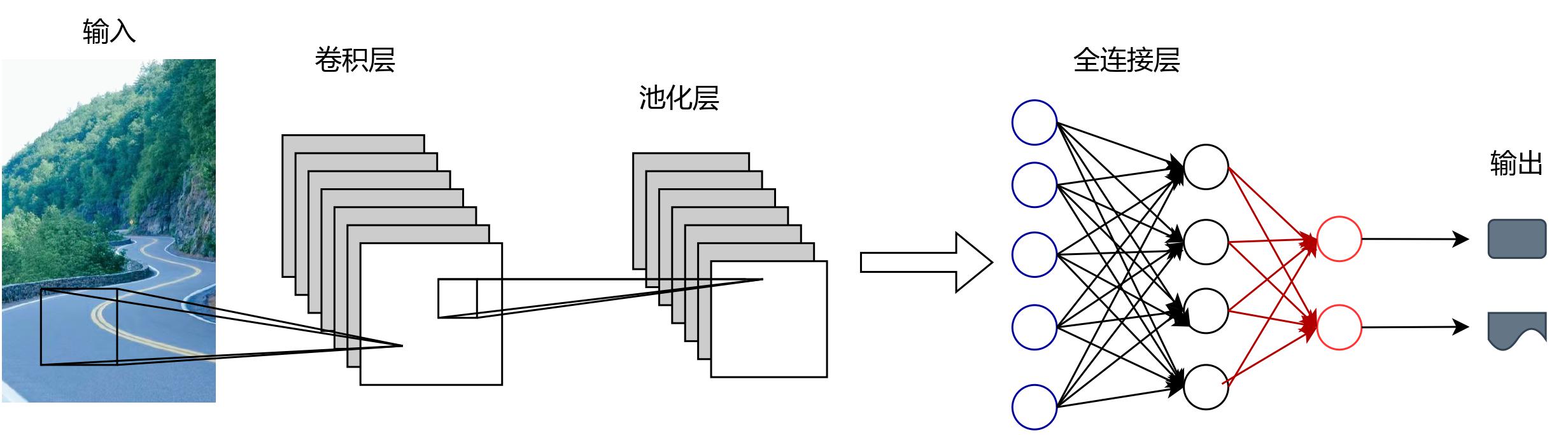 图3 卷积神经网络
图3 卷积神经网络